
Robustness of Magicの計算方法 (86PiBサイズのL1ノルム最小化問題を解く為には)
この記事は数理最適化 Advent Calendar 2023の19日目の記事です。
はじめに
本記事では、Robustness of Magicと呼ばれる量子情報で登場する指標を、どのようにして計算するかについてご紹介します。
これは物理分野の問題でありながら、数理最適化的な観点からもかなり面白い問題で、本記事が想定する読者の方々にも楽しんで頂けると思っています。話の9割以上は数理最適化のみに関するので、物理的な前提知識は一切必要ありません。
この内容は今年の11月にarXivにて公開された、私と友人と、東京大学大学院 工学系研究科 物理工学専攻助教の吉岡信行先生との共著による論文を基にしています。なお、ソースコード等はGitHub上で公開されています。
Robustness of Magicとは
まず、Robustness of Magic (RoM)について導入します。 といっても、この記事の想定読者は数理最適化を専門とされている方々です。なので、物理的な背景や量子情報における意義等は基本省略し、純粋な数理最適化の問題として以下説明していきます。物理的背景などは、論文や参考文献11,22をご参照下さい。
さて、Robustness of Magicは、次の $L^1$ノルム最小化問題 の最適値として定式化されます。
\begin{align*}
\min_{\boldsymbol{x}} & \quad \lVert\boldsymbol{x}\rVert_1 \\
\text{s.t.} & \quad A_n\boldsymbol{x} = \boldsymbol{b}
\end{align*}
$n$は量子ビット数に対応する自然数(本記事では$1 \leq n \leq 8$を満たす)で、 $\boldsymbol{b}$は長さ$4^n$のベクトル、 $x$は擬確率という量に対応する長さ$|\mathcal{S}_n|$ (定義は後述)のベクトルです。
そして、行列$A_n$は次のような形をしています。 $A_n$は$n$のみによって一意に決まり、$n=1,2$の場合は以下のようになります。

| 他の$n$についても似たような構造を有してます。つまり、$A_n$は$4^n$行$ | \mathcal{S}_n | $列の行列で、1列あたり$2^n$個の$\pm1$が存在する疎行列です。 |
ここで、$\mathcal{S}_n$は$n$量子ビットの純粋スタビライザー状態と呼ばれるものの集合として定義されており、重要なのは、
|\mathcal{S}_n| = 2^n \prod_{k=0}^{n-1} (2^{n-k}+1)
| という性質です。この$ | \mathcal{S}_n | $は非常に爆発的に増加し、具体的な値は以下の通りです。 |
| $n$ | $4^n$(行数) | $\lVert\mathcal{S}_n\rVert$(列数) | $A_n$(SciPyのCSC形式) |
|---|---|---|---|
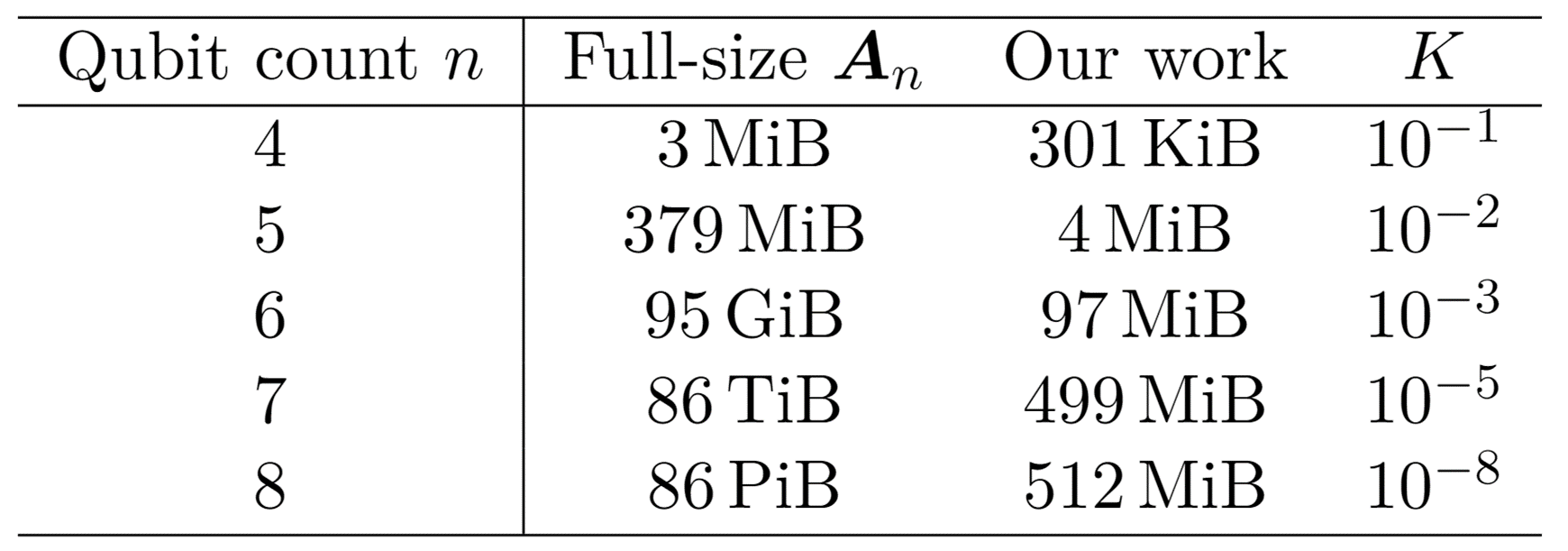
| 4 | 256 | 36720 | 3MiB |
| 5 | 1024 | 2423520 | 379MiB |
| 6 | 4096 | 315057600 | 95GiB |
| 7 | 16384 | 81284860800 | 86TiB |
| 8 | 65536 | 41780418451200 | 86PiB |
この記事を読むような方々には自然と伝わるかと思いますが、こんなサイズの問題を解くのは通常の場合、到底不可能です。時間をかければ解けるというレベルではありません。そもそもメモリに乗せられないのです。 悪質なコンピューターウイルスの一つとされるZIP爆弾のサイズでさえ4.5PiB程度なのですから、$n=8$での問題は、それをも軽く超えるデータサイズです。
既存研究では、$n \leq 5$が解ける限界とされており、密行列でのLPしか実装されていないSciPyに至っては$n=4$で既に限界が近いです。私も研究当初は、どんなに良くてもせいぜい$n=6$が限界だと思っていました。
しかし表題にもある通り、実はこの問題を $n=7$なら2時間程度、$n=8$なら2日程度で解けます。つまり、86PiBの$L^1$ノルム最小化問題を、割と真正面から解けるのです。
そこで本記事では、このように少し特殊な、そして、非常に莫大なサイズの$L^1$ノルム最小化問題をどのようにして解くかについて、その手法をご紹介します。 楽しんで頂ければ幸いです。
L1ノルム最小化問題の考察
それでは具体的な考察へと入っていきます。
まず前提として、$L^1$ノルム最小化問題は、補助変数を用いることで線形計画問題に帰着できることで有名です(参考記事)。 つまり、$|x_i| = x_i^+ + x_i^- \quad (x_i^+=\max(x_i,0), x_i^-=\max(-x_i,0))$として絶対値を外し、適当に変数を置き換えると、
\begin{align*}
\min_{\boldsymbol{u}} & \quad \sum_{i} u_i \\
\text{s.t.} & \quad \begin{pmatrix} A_n & -A_n\end{pmatrix} \boldsymbol{u} = \boldsymbol{b} \\
& \quad \boldsymbol{u} \geq 0
\end{align*}
となります。これは線形計画問題の等式標準形です。 よって、gurobiなどの疎行列用LP Solverを利用すれば$n \leq 5$で解けることが既存研究によって知られています。しかし、$n \geq 6$では$A_n$が巨大すぎるので、このままでは解けないという話でした。
LP Solverに行列を投げる前に、どうにかして問題サイズを小さくすることは出来ないのでしょうか?
ここで重要になるのが解の疎性です。 今回の$L^1$ノルム最小化問題は、基底追跡との別名もありますが、一般に解が疎になることで知られています。LASSOにおける正則化項が$L^1$ノルムであることなどもその事実に対応しています(参考記事)。
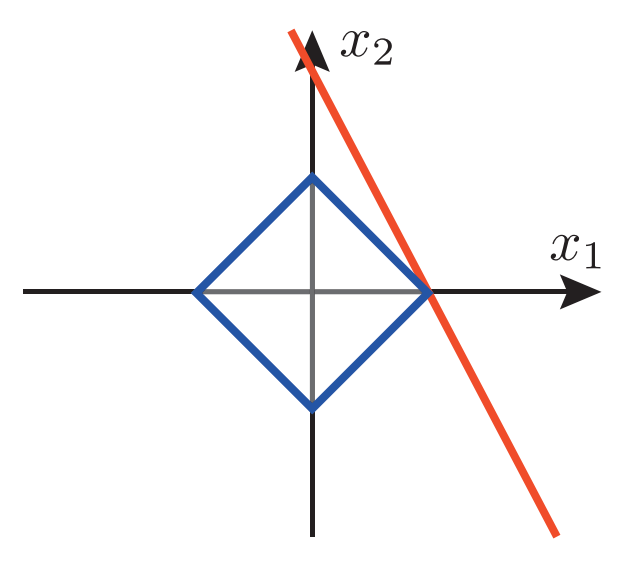 (赤線に最も$L^1$距離が近い点、つまり、赤線と青い四角の交差点は、確かに$x_2=0$と解が疎になっている)
(赤線に最も$L^1$距離が近い点、つまり、赤線と青い四角の交差点は、確かに$x_2=0$と解が疎になっている)
(出典: 大関 真之 .“今日からできるスパースモデリング”.京都大学大学院情報学研究科.http://www-adsys.sys.i.kyoto-u.ac.jp/mohzeki/Presentation/lectureslide20150902-3.pdf (最終アクセス日:2023年12月5日))
このように、解が疎であるという前提に立つと、もしある$i$が$x_i=0$を満たすならば、$A_n$の第$i$列は有っても無くても変わらず、予め削ってしまっても解に影響を与えないことが分かります。
この事実を利用して、何とか行列$A_n$を小さくしていきたいです。しかし、そもそも$x_i$が0になるかどうかは、解を求めるまでは分かりません。これでは堂々巡りです。どうにかして予め$x_i$が0になるかどうかを予測できないか?、というのが次なる考察に繋がります。
内積との関係性
ここで重要になってくるのが内積です。 これは以下の簡単な観察から、内積がこの予測に対して良い指標になることが分かります。
まず、$A_n \boldsymbol{x} = b$という制約式は、行列$A_n$の各列ベクトル$a_i$を$x_i$という重みによって線形結合して、ベクトル$b$にしていると解釈できます。特に今回の場合、行列$A_n$の第一行に注目すると$\sum_{i} x_i = 1$という制約があるので、アフィン結合になります。
この関係を図形的に表すと、以下のようになります。
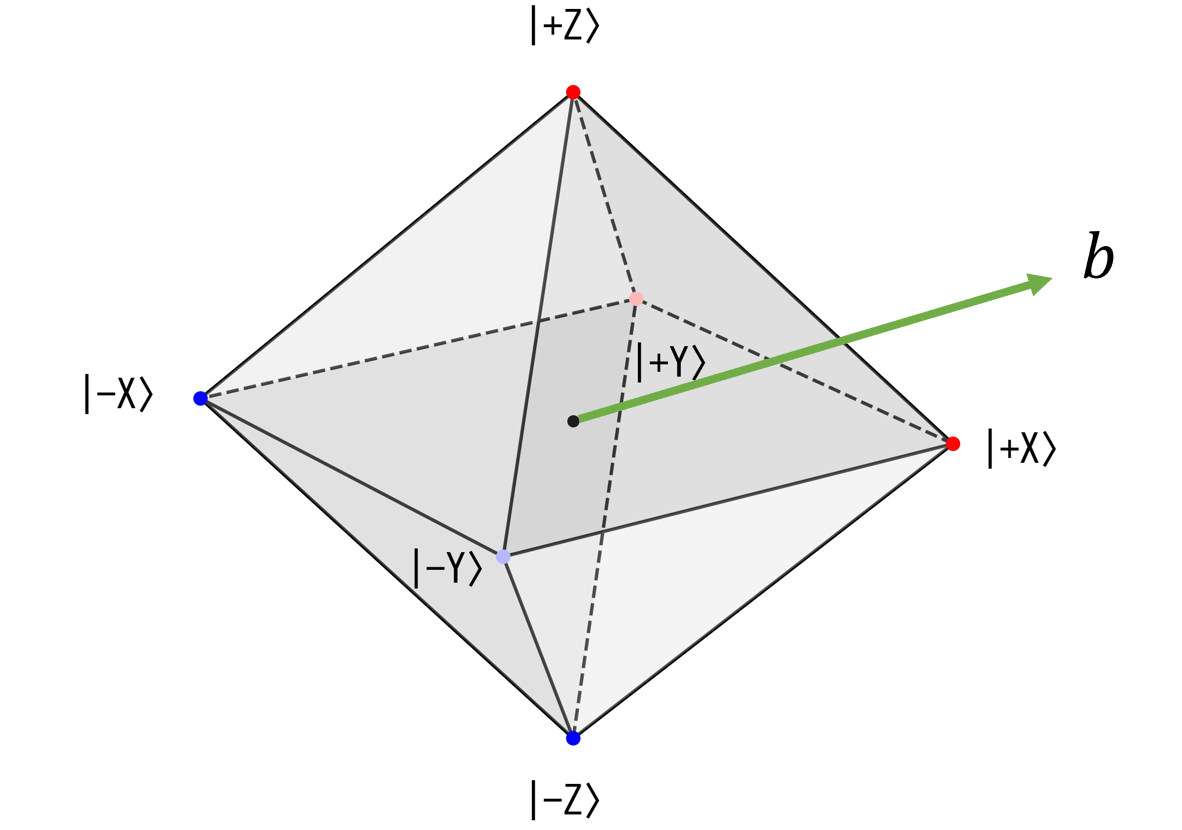
今、$\ket{+Y}$や$\ket{-Z}$などが$A_n$の各列ベクトルに対応しています(ベクトルを3次元の座標に見立てています)。そして、緑の矢印で表しているのが、ベクトル$b$です。 出来るだけ重み$\boldsymbol{x}$の絶対値の総和が小さくなるに、つまり、$L^1$ノルムが最小になるように、ベクトル$b$を表したいです。
すると当然ながら、$\ket{+X}$に割り振る重みを大きくしたくなります。$\boldsymbol{b}$に一番近い点が$\ket{+X}$になるからです。 特に今回は$\sum_{i} x_i =1$なので、$\ket{-X}$にも少し重みを足すと良さそうです。そして、$\ket{+Z}$や$\ket{+Y}$には辻褄合わせの分、さらに少しだけ重みを割り振り、$\ket{-Y}$や$\ket{-Z}$の重みを0にすると良さそうです。
このような直感をより数学的に表すと、$b$の$a_i$との内積(i.e., 直交成分)が、列ベクトル$a_i$の重要性を表していると考えられます。これはより高次元においても同様です。
実際、このような考察を裏付ける事実として、OMP(Orthogonal Matching Pursuit)というアルゴリズムがあります。これは元々、$L^0$ノルム最小化問題(つまり、$A\boldsymbol{x}=\boldsymbol{b}$を満たす最も疎な解を求める問題)を解くアルゴリズムであって、最大の直交成分を貪欲に取っていくアルゴリズムですが、$L^1$ノルム最小化問題に対しても、良い近似解をもたらすことが知られています(文献33,44)。
in Signal and Image Processing”. Springer. New York, NY (2010).
以上の議論より、RoM計算において内積の大小に着目することは有効ではないか、という仮説を立てられます。
内積との関係性を示す実験結果
実際にRoMと内積には関係があるのかどうか、数値実験で確認してみます。
ランダムに生成した $n=4$ での $\boldsymbol{b}$ に関して、RoMを与える擬確率分布 $\lbrace x_i \rbrace$ (縦軸)と、対応する行列 $A_n$ の列、つまり、純粋スタビライザー状態 $\sigma_i$ との内積(横軸)の関係を示したのが、以下の図です。
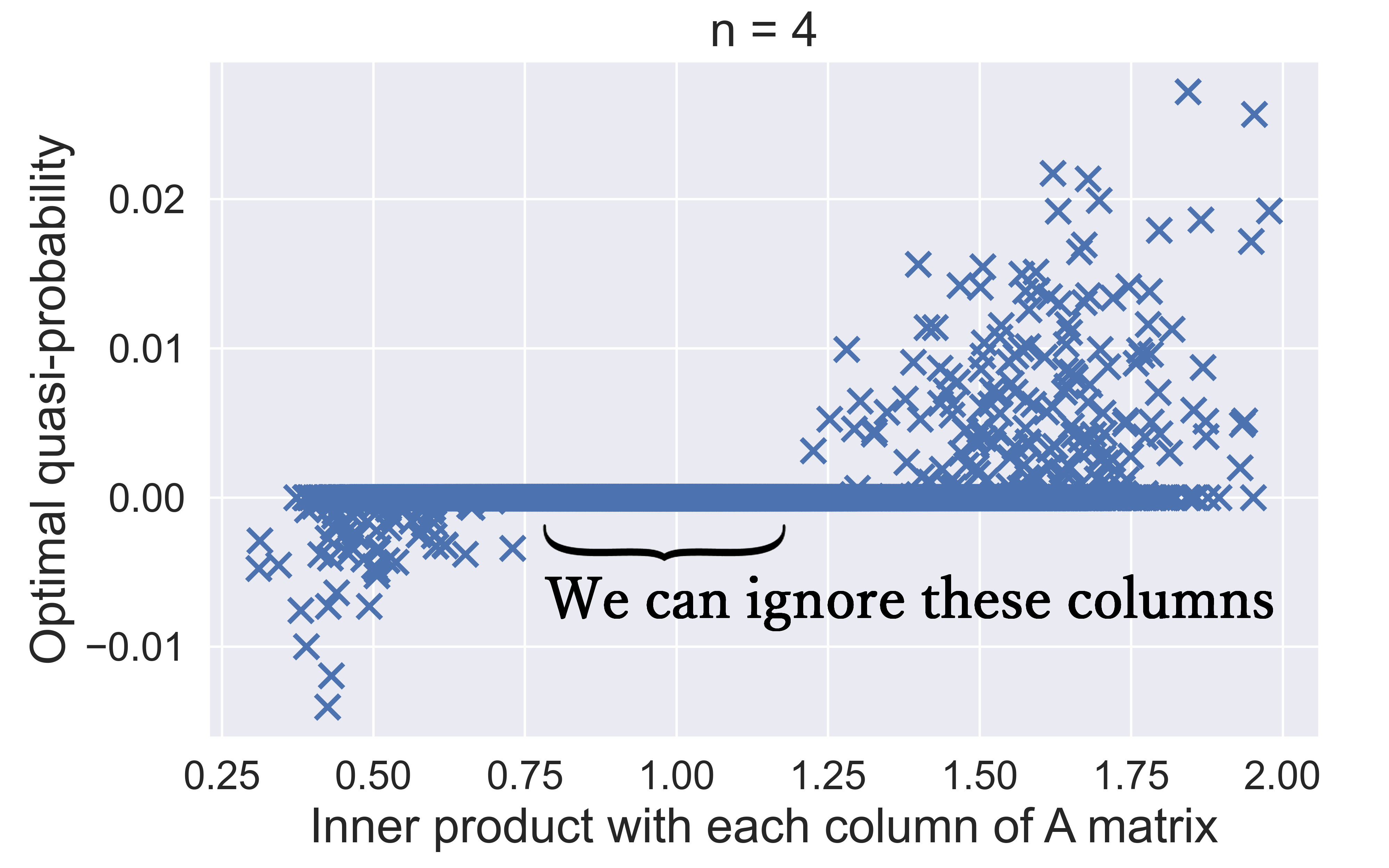
確かに、内積が大きい列と小さい列において、$x_i$の絶対値が大きくなる傾向があり、中途半端な内積を持つ列においては、殆ど全ての$x_i$が0になります。
なお、内積が大きい列だけでなく、小さい列も重要であるということは、ベクトル$b$に対してより直交的であるということから自然に理解出来ます。
以上からの議論から、当初の目論見通り、内積値が中途半端な列に対しては$x_i=0$になるだろうと予測できるので、事前に列を削っても解に殆ど影響を与えないだろうということが分かります。 よって、内積のtopKとbottomKだけを求めて、制限された主問題(RMP: Restricted Master Problem)を解くという素朴なアルゴリズムが自然に思い浮かびます。
内積の計算方法
さて、RoM計算における内積の重要性はこれで分かりましたが、まだ問題は山積しています。その内の一つが、そもそもどうやって内積を計算するか、という問題です。
| 行列$A_n$の$ | \mathcal{S}_n | $個ある列全てとの内積計算は、ナイーブに行うとそれだけで **$\mathcal{O}(2^n | \mathcal{S}_n | )$** という爆発的な時間計算量になってしまいます。 |
| しかし、上手い方法を取ることで、これを **$\mathcal{O}(n | \mathcal{S}_n | )$** にまで高速化出来ます。本節ではそれについて説明していきます。 |
行列の特殊性
ここで活用するのは、$A_n$の構造の特殊性です。$A_n$を再掲します。
この図をよく観察すると、$2^n$列ごとにブロックのようなものが形成されていることがお分かりいただけるでしょうか。 具体的には、$n=2$の最初の4列を取り出すと、図にあるインデックスを用いることで、
\begin{equation*}
\begin{pmatrix}
+II & +II& +II& +II \\
+IX & -IX& +IX& -IX \\
+XI & +XI& -XI& -XI \\
+XX & -XX& -XX& +XX
\end{pmatrix}
\end{equation*}
という、特殊な構造を持った行列が現れます。 その他の列でも、細かい符号の反転などはありますが、基本は同じように列が並んでいきます。
この性質を活用することで、高速化することを目指します。
FWHT
ここで登場するのが、 Fast Walsh Hadamard Transform (高速アダマール変換) という手法です。競技プログラミングをされている方なら、聞いたことがあるかもしれません。競プロ文脈ではこの記事などが有名です。
このアルゴリズムが行うのは、Walsh行列(Walsh Hadamard行列とも)に関する高速なベクトル行列積の計算です。
Sylvesterの方法で生成される(正規化されていない)Walsh行列は、クロネッカー積を用いて
\begin{align*}
H_1 & = \begin{pmatrix}
1 & 1 \\
1 & -1
\end{pmatrix},
\quad
H_k = H_{k-1}\otimes H_1 \quad (k \geq 2)
\end{align*}
と定義されます。緑を+1、赤を-1として、下図のような行列になります。
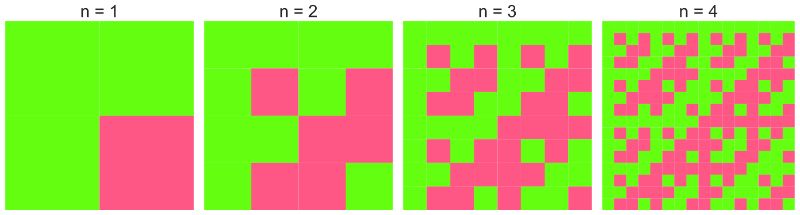
これと先程の行列を見比べると、確かに同じ構造を有していることが分かります。 (ちなみにこれは、行列$A_n$がスタビライザー群という群に対応している行列であり、群の各生成元について符号の任意性がある為に、自然に従う性質です)
そしてFWHTとは、この再帰的構造を用いて内積計算自体も再帰的に計算すればその分高速化する、ということを本質としたごく簡単なアルゴリズムです。上の行列($n=2$)と下の図解をよくよく見比べてもらうと、ご理解頂けるかと思います。
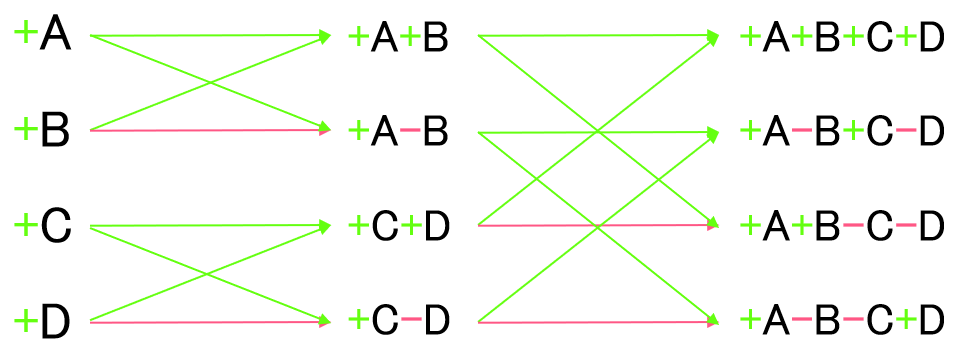
よって、通常掛かるはずの$\mathcal{O}(2^n \times 2^n)$の計算量を$\mathcal{O}(n 2^n)$に抑えられます。
参考までに、Pythonでの実装をWikipediaから引用しておきます。
PythonでのFWHTの実装
```python def fwht(a) -> None: """In-place Fast Walsh–Hadamard Transform of array a.""" h = 1 while h < len(a): # perform FWHT for i in range(0, len(a), h * 2): for j in range(i, i + h): x = a[j] y = a[j + h] a[j] = x + y a[j + h] = x - y # normalize and increment a /= math.sqrt(2) h *= 2 ```内積の計算時間
以上の事実を用いることで、十分に高速な内積計算が可能になります。
(……とは言え、実は「十分に高速」と言うにはまだギャップが存在します。 それは、そもそもどうやって行列$A_n$を生成するか、という問題です。 実際、この問題が一番の難関でした。 通常思いつくような方法で$n$から$A_n$を求めようとすると、内積計算の比ではない実行時間が掛かります。それではFWHTを用いたところで何の解決にもなりません。この問題の解決自体がそもそも元論文の一番の技術的貢献なのですが、物理的な前提知識を必要とする為、本記事ではおまけで少し触れるにとどめています。興味がある方は是非おまけもご覧下さい。)| 以上より、私の貧弱PCでも、2分程度で$n=7 ( | \mathcal{S}_n | \approx 8.1 \times 10^{10})$の内積計算が出来ますし、その5倍くらいの性能がある大学所有のPCでは、3時間半程度で$n=8 ( | \mathcal{S}_n | \approx 4.2 \times 10^{13})$の内積計算が出来ます。 |
高速な近似解法
ここまでくれば、前半戦は終了です。 内積を計算した上で、内積のtopKとbottomKに着目し、制限された主問題(RMP)を解けば、RoMの非常に良い近似値を得られます。
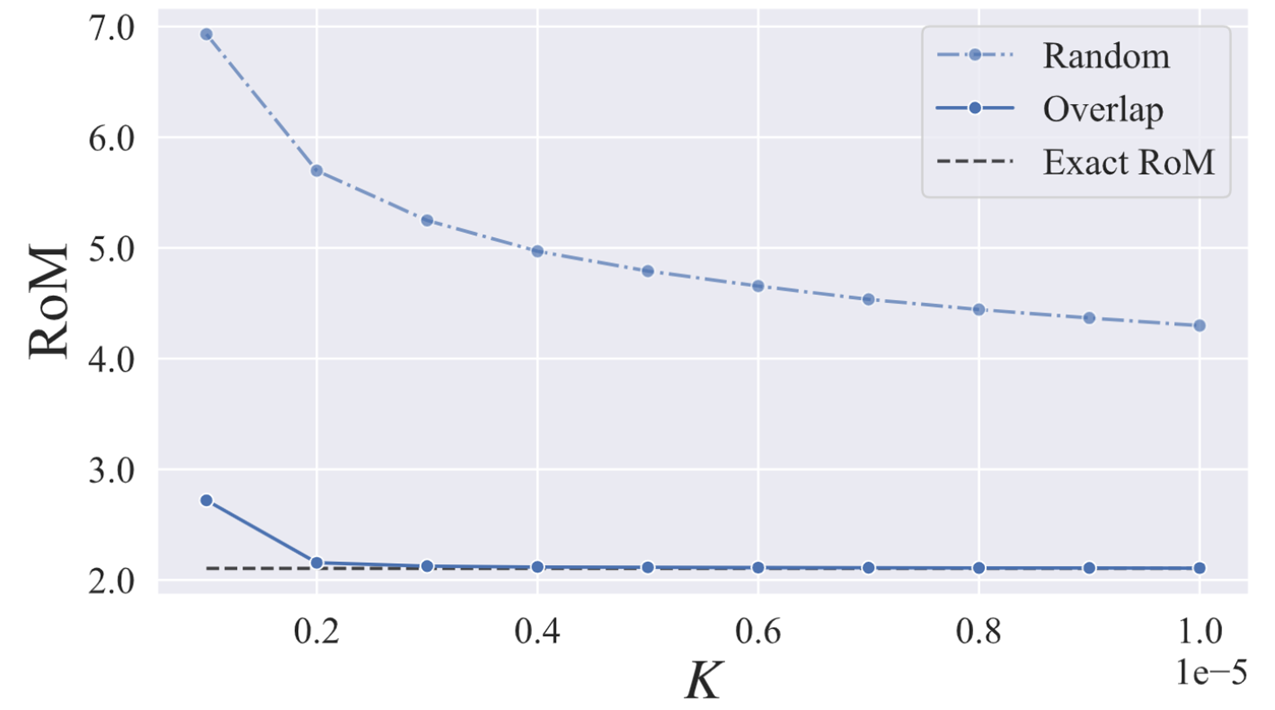
図が$n=7$における実験結果です。 Overlapが内積を用いた手法を表し、Randomがランダムに$A_n$の列を選択した場合を表しています。元の問題に対する制限された主問題のサイズが$K$(横軸)ですが、$K$が増える程、解(縦軸)は小さくなっています。 特に、内積に注目することで、ランダムに制限するよりも遥かに高速に近似的な最適値へと収束しています。
厳密解を得る為に
それでは、ここからが後半戦です。
先程で、ひとまずRoMの良い近似値を得ることが出来ました。しかし、これが最適値であるとは限りません。最適値を得るためには、どうすれば良いでしょうか?
ここまでの書き方からして、既にお察しの方も読者の方にはいらっしゃることでしょうが、解の仕上げとして列生成法と呼ばれる手法を用いていきます。 その説明を以下では行っていきます。
双対問題
列生成法の説明に入る前に、双対問題について簡単に説明します。
双対問題に詳しくない方は、是非以下の記事もご覧下さい。本記事も参加している数理最適化 Advent Calendar 2023の9日目の記事です。 とても分かりやすく、この節の内容を理解するのに必要な知識が全て書かれています。
さて、そもそものRoMを求める問題、つまり、主問題は以下のように定式化されました。
\begin{align*}
\min_{\boldsymbol{x}} & \quad \lVert\boldsymbol{x}\rVert_1 \\
\text{s.t.} & \quad A_n\boldsymbol{x} = \boldsymbol{b}
\end{align*}
この主問題の双対問題は以下のようになります。
\begin{align*}
\max_{\boldsymbol{y}} & \quad \boldsymbol{b}^\top \boldsymbol{y} \\
\text{s.t.} & \quad \left\lVert A_n^\top \boldsymbol{y} \right\rVert_\infty \leq 1
\end{align*}
なお、$\left\lVert\left\rVert A_n^\top \boldsymbol{y} \right\lVert\right\rVert_\infty \leq 1$は$-\boldsymbol{1} \leq A_n^\top \boldsymbol{y} \leq +\boldsymbol{1}$と同値です。
図でイメージするとこんな感じです。
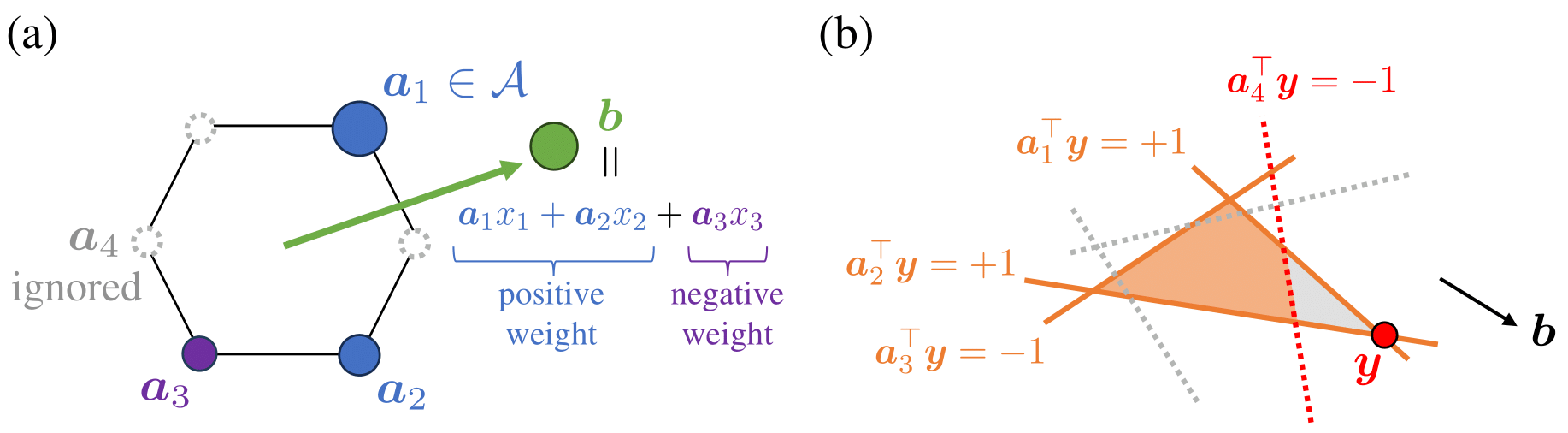
この図の意味を説明します。 まず、(a)は制限された主問題(RMP)を表しています。先程同様、$a_i$が行列$A_n$の列ベクトルに対応しています。主問題は、「行列$A_n$の各列ベクトル$a_i$を、出来る限り絶対値の総和が小さい重み$x_i$で線形結合して、ベクトル$b$を表せ」という問題だと解釈出来るのでした。列を制限することは、ベクトル$b$を表すために使える$a_i$を減らすことに相当します。
一方で双対問題は、(b)のように「行列$A_n$が表す多面体の内部に点$y$があるという制約下で、ベクトル$b$の方向に出来るだけ動かせ」という問題だと解釈出来ます。列を制限することは、この多面体の制限を緩和することに相当します。
これらが同一の問題だということを、強双対定理は(大まかには)主張しています。 そして、主問題において解をより小さくすることと、双対問題において解をより大きくすることは、同値であるということも(大まかには)言えます。
一般にこのような双対問題を考えることは、解の最適性の保証に対して有効です。 強双対定理より、今回の問題では最小化問題である主問題の解と、最大化問題である双対問題の解とが一致すれば、それらは共に最適解であることが分かります。この性質を使って、RoMの近似値を最適値へと仕上げていきます。
なお、厳密な議論などは省きましたが、双対問題などに関するより詳細な説明としては、梅谷 俊治先生(数理最適化 Advent Calendar 2023の最終日をご担当)による『しっかり学ぶ数理最適化―モデルからアルゴリズムまで』などもご参照下さい。
双対変数の意味と列生成法
さて、このように導入した双対問題ですが、これの最大の嬉しさは最適解に達するために必要な列を見つけられるという点です。そしてそれが列生成法の本質だと私は考えています。
もう一度、先程の図を用いて説明します。 まず、制限された主問題($a_4$を削った問題)を解いて、対応する双対変数$\boldsymbol{y}$が得られたとします。双対問題において、$a_4$を削ることは、制約を緩和することに対応していたことを思い出して下さい。すると、点$\boldsymbol{y}$がこのような多面体の頂点に来ることが分かります。
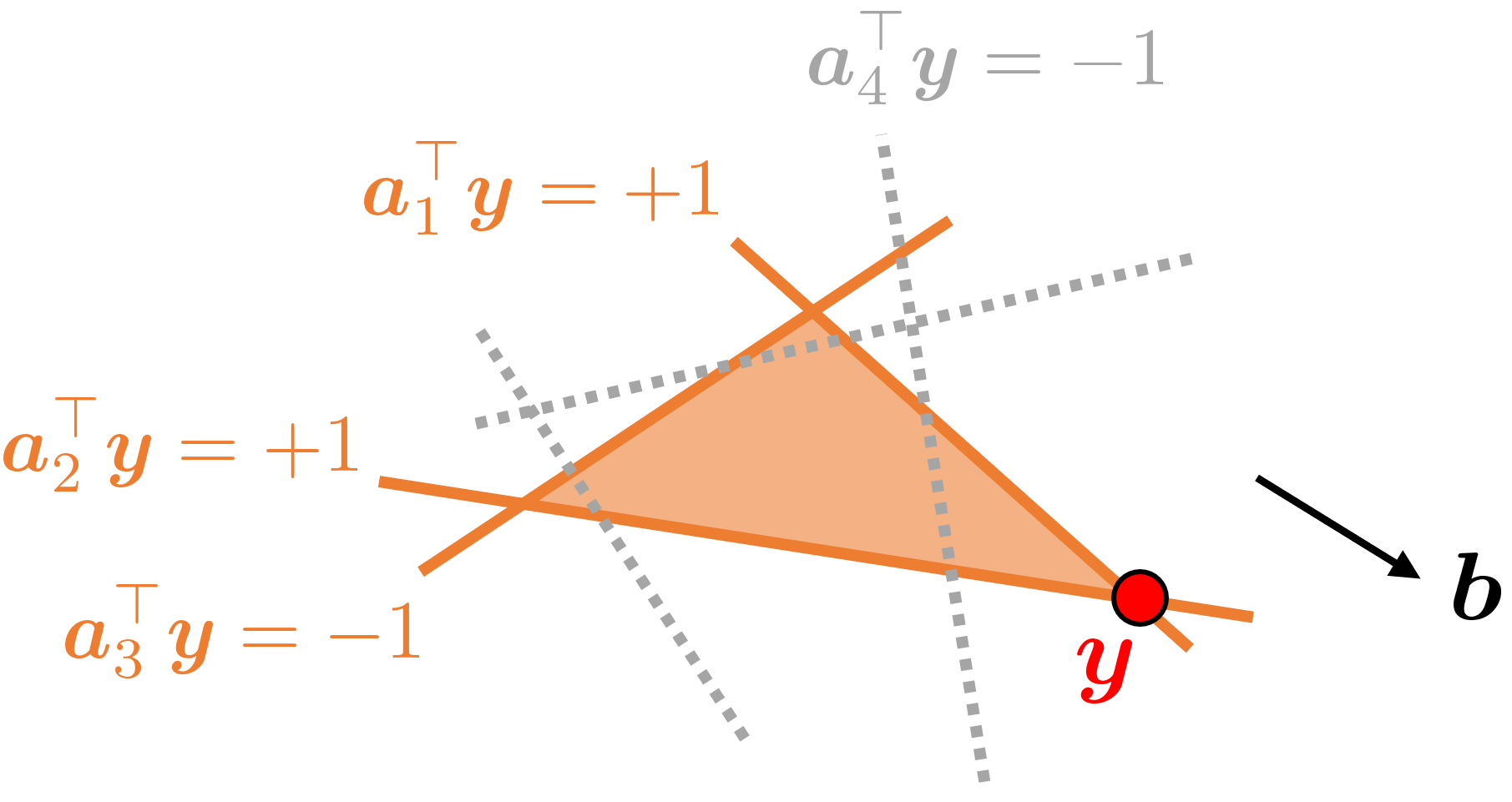
この時、無視した行列$A_n$の列に関する制約は、当然満たされているとは限りません。いくつかの制約に関しては、$\left\lVert a_i^\top \boldsymbol{y} \right\rVert > 1$となってしまっていることがあります。この場合、$\boldsymbol{y}$が$a_4$の表す制約(灰色の点線)の外に来てしまっているので、削っていた$a_4$が実は必要な制約であったと分かります。
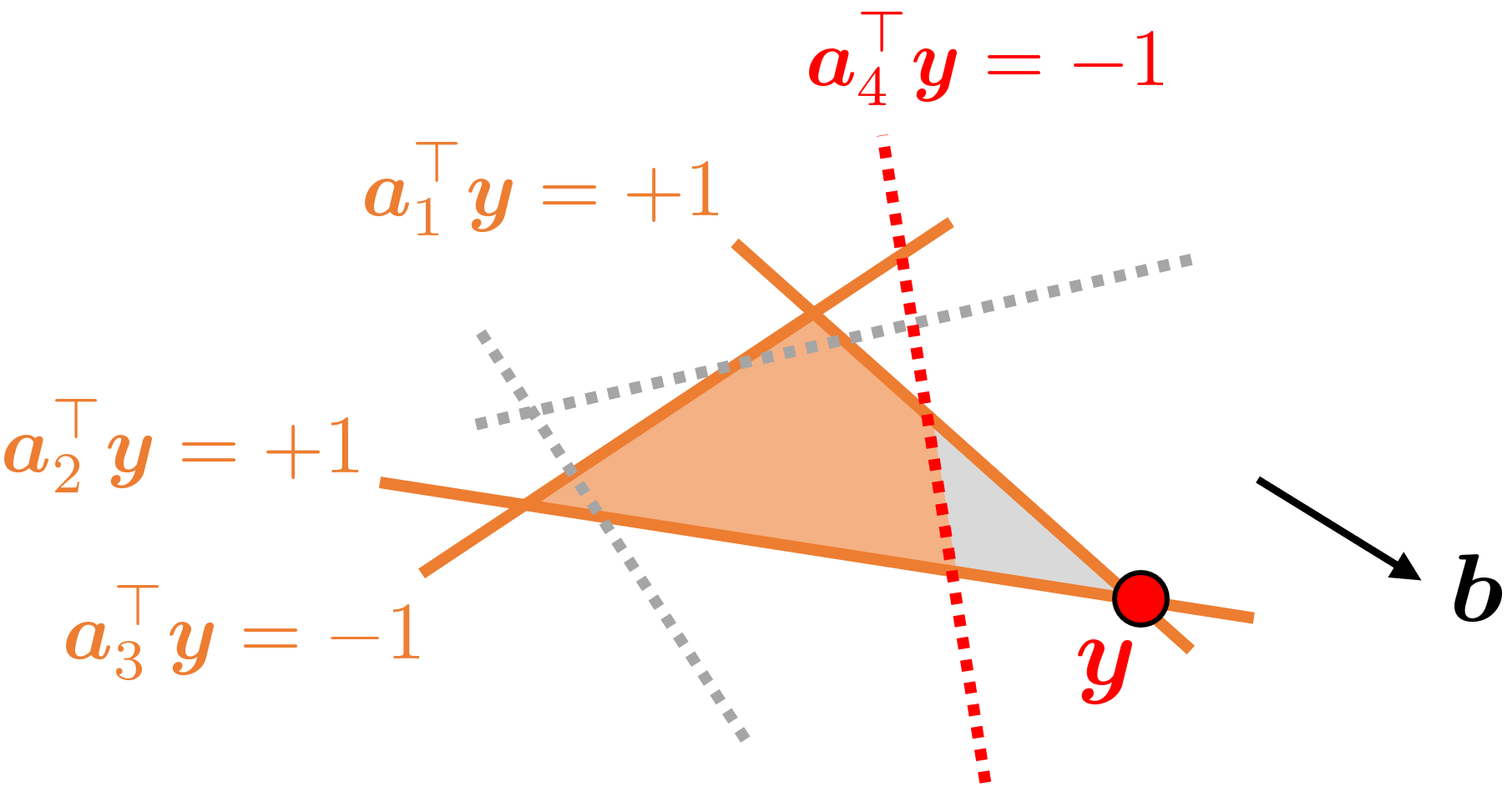
そこで、この違反している制約だけを追加した問題を考えます。実装上は、主問題側で列を増やして再最適化するだけです。 すると、再最適化の結果として、今度はきちんと制約を全て満たした解が得られます。
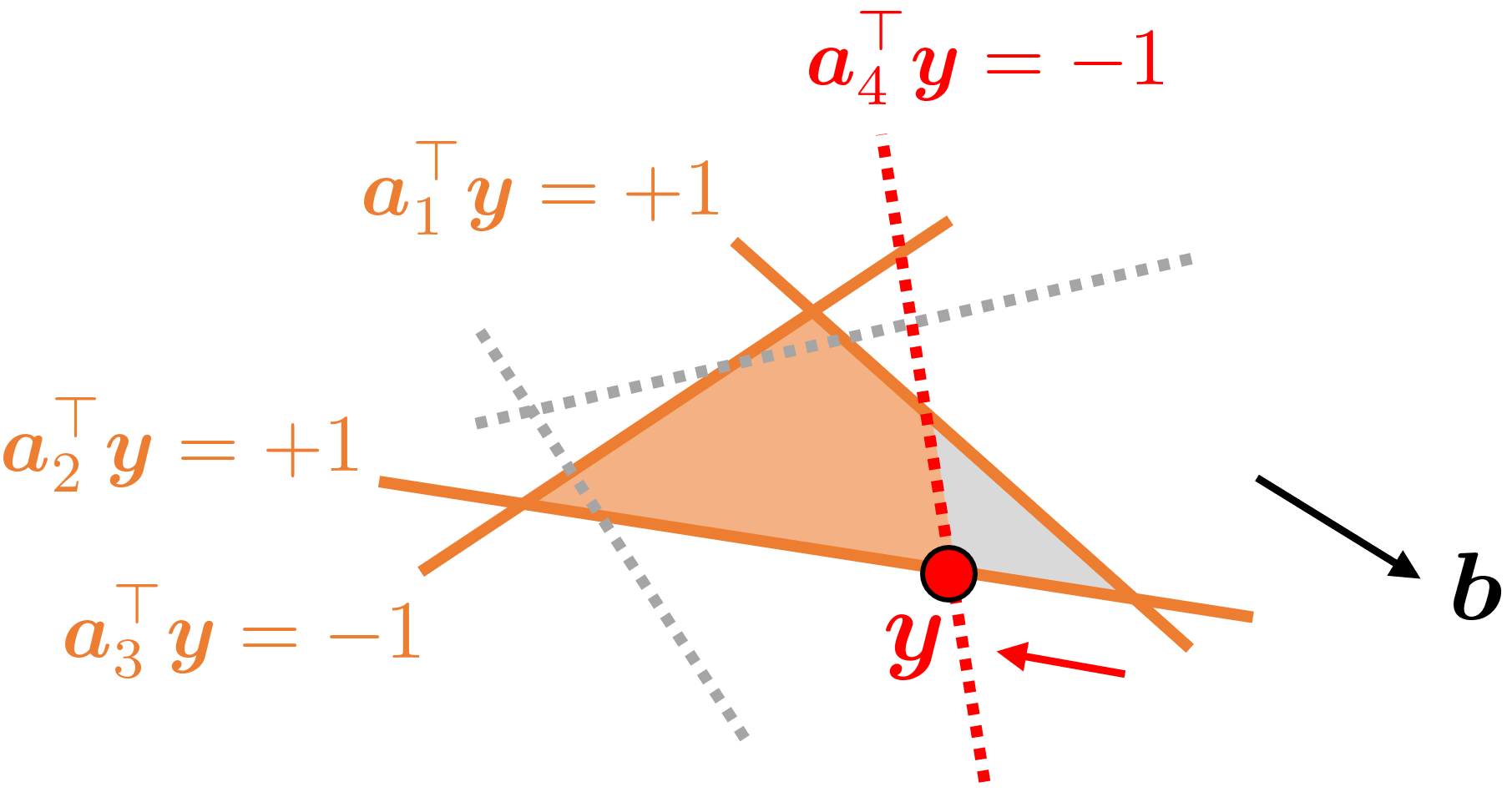
強双対定理より、この解は元の主問題の解と一致します。つまり、双対変数が発見する「違反した制約」を加えるという操作をすると、双対問題の最適値がより小さくなる、すなわち、主問題における最適値もより小さくなるということが分かります。
誤解を恐れずに大雑把に言えば(今回の)列生成法は双対変数に着目した賢い反復解法です。主問題だけを考えていては「最適解に達するために必要な列」というのを発見することは極めて困難ですが、双対変数を利用することでそれが明らかになります。
また、全ての列が違反しなくなれば、主問題においても解が最適であるということが分かるので、それまで列の生成を繰り返すことで、最適解を得られます。
このように、最初はヒューリスティックな解だったものが、双対変数を考えることで、厳密性が保証された解へと仕上がっていきます。これが、列生成法の非常に面白いところです。
先述した9日目の記事にもある通り、「双対変数はある制約式の右辺を微小に変化させた際の、対応するコスト関数の変化分の比率を表す量」だというイメージがあれば、列生成法もより直感的に理解出来るかもしれません。
なお、列生成法は本来もう少し抽象的なアルゴリズムを指します。 NTT DATAによる列生成法の説明ページから、以下を引用します。
(列生成法とは)制約付きネットワークフロー問題やカッティングストック問題など,解が特徴的な構造を持つ「部分解」の重ね合わせとして表現できる性質を利用して大規模な問題を解く技法. ……列生成法はラグランジュ緩和法と密接に関連しており,……「双対変数」は,ラグランジュ緩和法で更新するラグランジュ乗数に他ならない. また,ラグランジュ乗数の更新に劣勾配法でなく微分不可能な凸関数に対する切除平面法を用いれば,ラグランジュ緩和法は列生成法と等価となる.
(出典: NTT DATA .“列生成法”.株式会社NTTデータ数理システム. https://www.msi.co.jp/solution/nuopt/glossary/term_c0e28a677d7bb9413599d401d369064e5c597032.html (最終アクセス日:2023年12月18日) (一部改変))
他の列生成法に関する説明としては、以下の宮本 裕一郎先生による『はじめての列生成法』や、
電気通信大学の岡本 吉央先生によるスライド
なども参考になります。より詳細に知りたい方は、是非ご参照下さい。
ちなみに、列生成法が適用できると最初に気付いたのは共著者の友人でした。彼はこの手法を自力で再発明したらしく、相変わらず凄いものです。
実験結果
以上を基に列生成法を実装し、先述の高速な内積計算などと組み合わせた結果が、以下に示す実験結果です。
制限された主問題のサイズを表すパラメータ$K$は、下表のように設定しました。 これは各イテレーション毎の、新たに追加する列数の上限にも対応しています。実装では、途中途中で不要な列というのも出てくるのでそれらは捨てています。
動作結果は以下の通りです。

左図が$n=7$、右図が$n=8$における実験結果です。 列生成法のイテレーション数(横軸)毎に目的関数値と制約の違反数が減少しています。 特に、制約の違反数は指数的に減少していき、最終的には0に収束するので、これで最適解だということが分かります。
ということで、40スレッドを有する大学のPCを使って、元々は86PiBの問題だった、$n=8$におけるRoM計算は、各イテレーション毎に内積計算が3時間半、LP計算が1時間程度と、合計2日ほどで最適値を得られます。
やりました!
最後に
以上、Robustness of Magicの計算方法についてご紹介しました。 本記事を通して、量子情報分野における最適化問題の面白さを少しでも感じて頂けたら幸いです。
ここまでお読み頂きありがとうございました。
残りは個人的な備忘録も兼ねたおまけとなります。 もしご興味があれば、お付き合い頂ければ幸いです。
おまけ
おまけとして、4点ほど裏話をして、本記事を終わりにしたいと思います。
q二項係数との関係性
最初に記すのは、本文でも触れたどのようにして$A_n$を高速に生成するのかというお話です。これは非常に重要で、単にFWHTや列生成法を使うだけでは、実はこの問題には全く歯が立ちません。
この記事を読んで下さる数理最適化の専門家の方には、「なんだ、ただ列生成法をちょっと工夫して適用しただけじゃん」と思われるかも知れないのですが、実は必ずしもそういう訳ではないのです。$A_n$を高速に生成するというこの部分こそが、ある意味で一番の本質であり難関でした。 この項では、その難関をどうやって乗り越えたか、ということをご説明します。
そのために重要な考察が、q二項係数との関係性です。
論文では省略した定理の一つに、以下の定理があります。 これは文献55のAppendixにおいてもほぼ同様のことが証明されていますが、それを私は再発見しました。
まずはその定理をご紹介します。
:::note info 定理
$n$量子ビットの純粋スタビライザー状態の集合$\mathcal{S}_n$から、独立に2つの状態$\sigma_1, \sigma_2$を一様サンプリングする。 この時、$\langle \sigma_1 | \sigma_2 \rangle$という確率変数の期待値は1となる。 :::
これだけ見ても何の話だか分かったものではありませんが、一度詳細は後回しにして、まずはこの定理が成り立つことを証明します。
証明
| $\genfrac{[}{]}{0pt}{}{n}{k}_2$でq=2の場合のq二項係数を表すとする。また、ある$\sigma_1$に対し、$\mathcal{L}_n(k)$で$\langle \sigma_1 | \sigma_2 \rangle = 2^{n-k}$になるような状態$\sigma_2$の個数を表すとする。なお、この$\mathcal{L}_n(k)$は$\sigma_1$に依らず |
\mathcal{L}_n(k)=2^{k(k+3)/2}\genfrac{[}{]}{0pt}{}{n}{k}_2
であることが証明できる。
すると、
\begin{align*}
E[\langle \sigma_1 | \sigma_2 \rangle] & =\frac{\sum_{k=0}^{n} 2^{n-k}\mathcal{L}_n(k)}{|\mathcal{S}_n|} \\
& =\frac{
2^n\sum_{k=0}^{n} 2^{\frac{k(k+1)}{2}} \genfrac{[}{]}{0pt}{}{n}{k}_2
}{
2^n \prod_{k=1}^{n}(1+2^k)
} \\
& =1
\end{align*}
となる。 ただし、コーシーの二項定理を最後に用いた。
この定理の意義
さて、以上、謎の定理を謎の理論で証明しましたが、実はこの定理は非常に重要な意義を持ちます。主張内容自体の物理的意味はかなり薄いのではないかと考えていますが(そしてそれ故に論文では省略していますが)、研究の流れにおいてはNo.1の意義を持ちます。 というのも、もし私がこの定理を発見できていなければ、RoM計算は$n \leq 6$が限界だと私は結論付けていたことでしょう。
この定理が一体何を言っているかについてご説明します。 冒頭でもお見せした行列$A_n$を再掲します。
この定理の主張内容を言い換えると、$A_n$から任意に2つの列をとってきて、その内積を計算すると、期待値が丁度1になる、ということを言っています。確かに、$n=1$の場合だと、確率$1/6$で内積が2、$4/6$で内積が1、$1/6$で内積が0となり、期待値は0になります。より$n$が大きくなっても、期待値は丁度1になります。
これは本当に不思議な現象です。私は偶然にこの現象を発見しましたが、最初はバグとしか思えませんでした。そしてそれがバグではないと気付いた時には、この行列の背後に潜む数学的な構造に感嘆しました。
事実としてこのような現象が成立するので、逆算して一体何故このようなことが起きるのかを考えます。すると、最終的には証明でも使用した、コーシーの二項定理から導かれる関係式
|\mathcal{S}_n| = 2^n \prod_{k=0}^{n-1} (2^{n-k}+1) = 2^n \sum_{k=0}^{n} 2^{\frac{k(k+1)}{2}} \genfrac{[}{]}{0pt}{}{n}{k}_2
に辿り着きます。この等式こそが、この定理のもたらす真の果実です。
(以下の説明は量子情報の前提知識を必要としてしまいますが、) この等式は純粋スタビライザー状態という状態が、stabilizer tableau6と呼ばれる$\mathbb{F}_2$上の行列の、行簡約階段形(RREF行列)を基にした形式と一対一対応することを示唆しています。そして、q二項係数はこのような行列の種類数と関係することが知られています。
ここからスタビライザー状態(スタビライザー群)がどのような構造を有しているかが分かるので、その効率的な列挙を行うアルゴリズムが導出可能になり、$A_n$という超巨大な行列を、$n=8$でも高々数時間程度で事前計算無しに構築出来ます。自分で言うのは少々烏滸がましいですが、かなり驚異的な結果だと思います。
もしも詳細に興味がある方は、元論文のAppendixや、q二項係数の記事1,記事2、q二項定理のwikiなどをご参照下さい。
……正直、この話の数学的な意義や美しさを十分に共有することは、(広範な事前知識が必要という意味において)難しいかと思います。
しかし、本当に偶然に発見した、一見すると無意味で不思議な現象が、次々と背後の数理的な構造を暴き、終いには圧倒的に高速なアルゴリズムを導出するまでに至ったとなれば、それはそれで面白い話だと思いませんか? このアルゴリズムの導出に至るまでの道は、割と誇張抜きで地獄でしたが、ついにアルゴリズムが動作した時の感動は忘れがたいものです。競プロで培った定数倍高速化技術を総動員したのも面白かったです(競プロは研究の役に立つ)。
そんなくだらない雑感を、これを読んで下さっている方と共有できたのであれば、本項の目的は達成です。
ANSIエスケープシーケンスの罠
おまけの2個目は、プログラムの開発時に遭遇した、奇怪なバグについてです。
そのバグは簡潔に言い表すと、「ANSIエスケープシーケンスの罠を踏むと、VSCodeを開くか閉じるかで実行時間が2倍も変わる」というものです。 これは結構不思議な話で、私視点から言えばプログラムの実行を見張っていると正常に動く癖に、これを見張らないと実行時間が2倍になるという、一体何なんだと言いたくなるようなバグでした。
発生条件などを完全に解析で来ている訳ではないので、確実な再現性があるかどうかは不明です。少なくとも私の環境では、以下のコードの実行時間が、ターミナルを開くか閉じるかだけの違いで2倍程度の有意差が出ることを確認しています。
import time
def log(i, d):
# ANSIエスケープシーケンスを使ったカーソル移動
print(f"\033[1F\033[0K i = {i}, d = {d}")
def main():
t0 = time.perf_counter()
for i in range(1000):
# 適当な処理
d = 0
for j in range(10000):
d += j**0.5
# ログ出力
log(i, d)
t1 = time.perf_counter()
print(f"duration = {t1 - t0}[ms]")
if __name__ == "__main__":
main()
| open | closed | |
|---|---|---|
| 画面 | <img width=100% src=”https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/905155/02629993-fcaa-6911-cd80-a06d4051613c.png” alt=”open”> | <img width=100% src=”https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/905155/a93316b8-54d8-55b5-ecea-d1403f055df1.png” alt=”closed”> |
| 実行時間 | 8秒前後 | 4秒前後 |
実際のバグでは、上の結果とは逆に画面を開いている時の方が実行が速く、バグの特定にはかなり苦労しました。 ANSIエスケープシーケンスは出力に色付け出来たり、カーソルを移動できたりととても便利なのですが、こういう罠がある事には注意が必要そうです。
argpartitionについて
おまけの3個目は、topKの求め方についてです。
今回の話では、内積のtopKなどを求めたいという話がありました。 一般に、ある$N$個の要素を持つ配列に対して、その中で値が大きい方から$K$個の要素を求めたいという状況は多いです。
ネットを検索すると、例えばPythonでは、np.argpartitionを使うと良いという記事が多く見られます。実際、ソートの計算量は$\mathcal{O}(N\log N)$ですが、np.argpartitionを使うと$K \ll N$の仮定の下で$\mathcal{O}(N)$で済み、高速です。
これでめでたく内積のtopKを求められました。 ……という話であれば幸せだったのですが、実はそうは簡単にいきません。 今回の問題における要素数$N$とは、則ち$|\mathcal{S}_n|$で、これは$n=8$で4e13を超えます。定数倍の重いnp.argpartitionでは遅すぎるのです。
どれだけ定数倍を高速にこのtopKを求めるかという問題には、かなり最後まで悩まされました。
私が取った大まかな方針としては、事前に閾値を設定するという非常に単純なものです。しかし、これはかなり汎用性がある割には、検索してもあまり出てこないと思います(私は見つけられていません)。なので、ここで軽く紹介しておきます。
具体例として、$N$個の0以上1未満の一様乱数に対して、値が大きい方から$K$個の要素を求めたいとします。この時、$N$が十分大きければ$K$個の要素は全て0.99よりも大きいという仮定が高確率で成立します。なので、以下のようなコードが考えられます。
def topK_argpartition(data, k):
# O(N)
args = np.argpartition(data, -k)[-k:]
return data[args]
def topK_threshold(data, k):
# 適切な閾値を事前情報から推定
threshold = 0.99
data_large = data[data > threshold]
if len(data_large) < k:
# 削りすぎてしまった場合(失敗)
return topK_argpartition(data, k)
else:
# 閾値を超えるデータがk個以上ある場合(成功)
return topK_argpartition(data_large, k)
この簡単な措置だけでも、実はかなりの高速化に繋がります。 次のグラフがその実験結果です。
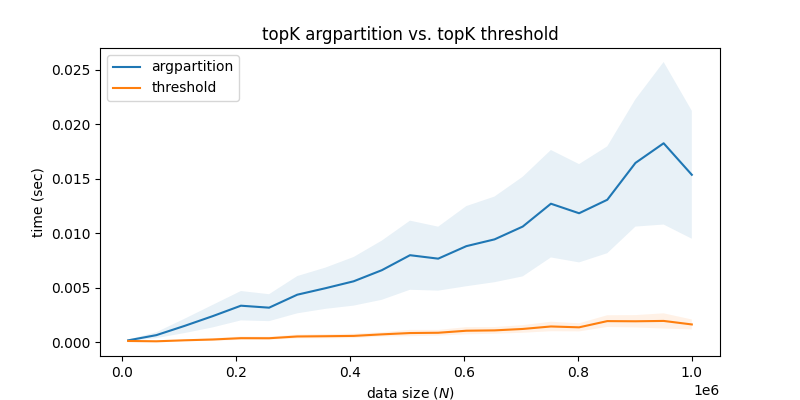
実験コード
```Python import numpy as np def topK_argsort(data, k): # O(N log N) args = np.argsort(data)[-k:] return data[args] def topK_argpartition(data, k): # O(N) args = np.argpartition(data, -k)[-k:] return data[args] def topK_threshold(data, k): # 適切な閾値を事前情報から推定 threshold = 0.99 data_large = data[data > threshold] if len(data_large) < k: # 削りすぎてしまった場合(失敗) return topK_argpartition(data, k) else: # 閾値を超えるデータがk個以上ある場合(成功) return topK_argpartition(data_large, k) def main(): import time import matplotlib.pyplot as plt NUM_SEED = 300 k = 100 mean_times_argpartition = [] mean_times_threshold = [] ub_times_argpartition = [] ub_times_threshold = [] lb_times_argpartition = [] lb_times_threshold = [] Ns = np.linspace(1e4, 1e6, 21) for _n in Ns: print(f"n={_n}") n = int(_n) times_argpartition = [] times_threshold = [] for seed in range(NUM_SEED): # 0以上1未満の一様乱数をn個生成 np.random.seed(seed) data = np.random.random(n) t0 = time.perf_counter() ans_argpartition = topK_argpartition(data, k) t1 = time.perf_counter() times_argpartition.append(t1 - t0) t0 = time.perf_counter() ans_threshold = topK_threshold(data, k) t1 = time.perf_counter() times_threshold.append(t1 - t0) assert np.allclose(np.sort(ans_argpartition), np.sort(ans_threshold)) mean_argpartition = np.mean(times_argpartition) mean_threshold = np.mean(times_threshold) std_argpartition = np.std(times_argpartition) std_threshold = np.std(times_threshold) ub_argpartition = mean_argpartition + std_argpartition ub_threshold = mean_threshold + std_threshold lb_argpartition = mean_argpartition - std_argpartition lb_threshold = mean_threshold - std_threshold mean_times_argpartition.append(mean_argpartition) mean_times_threshold.append(mean_threshold) ub_times_argpartition.append(ub_argpartition) ub_times_threshold.append(ub_threshold) lb_times_argpartition.append(lb_argpartition) lb_times_threshold.append(lb_threshold) plt.figure(figsize=(8, 4)) plt.plot(Ns, mean_times_argpartition, label="argpartition") plt.plot(Ns, mean_times_threshold, label="threshold") plt.fill_between(Ns, lb_times_argpartition, ub_times_argpartition, alpha=0.1) plt.fill_between(Ns, lb_times_threshold, ub_times_threshold, alpha=0.1) plt.xlabel("data size ($N$)") plt.ylabel("time (sec)") plt.legend(loc="upper left") plt.title("topK argpartition vs. topK threshold") plt.savefig("argpartition.png") if __name__ == "__main__": main() ```今回は一様乱数を仮定したので、こう書くと至極当然な話ではあります。 しかし、状況に応じて適切に事前分布を設定した上で、最適な閾値を模索し処理する事は、非常に膨大なデータを扱う上で一つの有効な手法だと思います。実装では、このような事実とその他いくつかの工夫を組み合わせることで、内積のtopKを高速に求めました。
gurobiのチューニングについて
最後に記すのは、gurobiのチューニングについてです。
数か月前の自分に言ってやりたいのは、同じ様な問題を繰り返す解く際は、必ずmodel.optimize()をしろ!、ということです(公式マニュアル)。私はこれで多くの時間を無駄にしました。
gurobiはpresolveという前処理フェーズがデフォルトで有効になっていますが、今回のRoM計算においては、完全に不要な処理です。なので、これをmodel.optimizeの結果に従ってOFFにすることで、格段に実行が高速になります。
gurobiは、研究目的とは言え無償で提供されていることが信じられないくらいには高性能なSolverですが、その扱いは少し難しいですね……。
また、本当はLPのwarm startをやりたかったのですが、どうやるのが正解か分からず諦めました(あるいは出来ていた上で逆効果だったのかも知れません)。列生成法との相性は良いらしい(参考記事)のですが、今回は出来ませんでした。
いつかgurobiを完全に使いこなすことが、私の目標です。
以上、これにて本当の最後となります。
最後までお読み頂きありがとうございました。
Mark Howard and Earl T. Campbell. “Application of a resource theory for magic states to fault-tolerant quantum computing”. Physical Review Letters 118, 090501 (2017). ↩
Hakop Pashayan, Joel J. Wallman, and Stephen D. Bartlett. “Estimating outcome probabilities of quantum circuits using quasiprobabilities”. Physical Review Letters 115, 070501 (2015). ↩
Michael Elad. “Sparse and Redundant Representations: From Theory to Applications ↩
David L. Donoho and Yaakov Tsaig. “Fast Solution of \ell 1 -Norm Minimization Problems When the Solution May Be Sparse”. IEEE Transactions on Information Theory 54, 4789–4812 (2008). ↩
G.I. Struchalin, Ya. A. Zagorovskii, E.V. Kovlakov, S.S. Straupe, and S.P. Kulik. “Experimental Estimation of Quantum State Properties from Classical Shadows”. PRX Quantum 2, 010307 (2021). ↩
Scott Aaronson and Daniel Gottesman. “Improved Simulation of Stabilizer Circuits”. Physical Review A 70, 052328 (2004). arxiv:quant-ph/0406196. ↩